Concurrency Implementation
Overview
My first implementation crawled a domain page by page. It worked fine for small websites like this portfolio, which has around 20 pages, completing in about a second on average. The performance problem became more apparent when I tried crawling a site with roughly 42,000 pages which took around 1 hour and 20 minutes to complete. To address this, I extended the implementation to support concurrency, allowing the crawler to analyse multiple pages simultaneously. This significantly improved both the speed and scalability of the program.
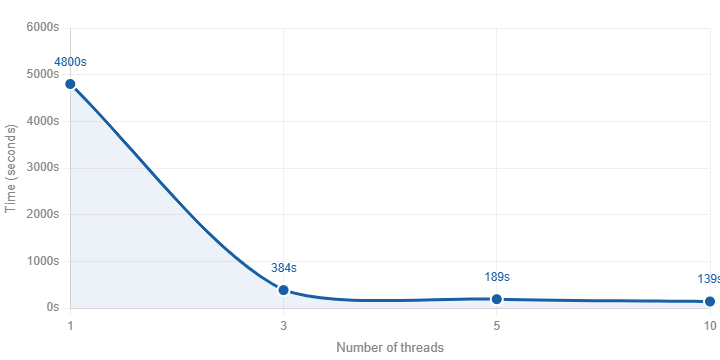
Crawl Performance Comparison for Domain with 42k Pages
Going from a single thread to just three made a massive difference, dropping from 4800 seconds all the way down to 384 seconds.
After that, adding more threads still helped, settling at 139 seconds with 10 threads.
Beyond 10 threads, the performance gains become increasingly smaller while resource consumption continued to rise.
I wanted to keep a good balance between performance and resources usage (such as memory, network and overwhelming target website).
10 threads delivered a 34× speedup over single-threaded execution without putting unnecessary strain on the system.
Conclusion
This was a fun little project I completed in a few days. I was able to use concurrency to boost the performance of this application while also becoming more familiar with Java. There are a few things that could be improved in the future, such as respecting robots.txt rules and adding crawl delays to ensure the crawler behaves responsibly toward websites, or adding depth limits and page limits to control how large the crawl can grow and avoid excessive resource usage.