Website Crawler
General Overview
A web crawler is an automated program that browses the internet by visiting web pages and following links from one page to another. Search engines use crawlers to discover new content, update their indexes, and help users find relevant information quickly. Crawlers can also be used for tasks like price monitoring, data collection, website audits, and content aggregation.
My Web Crawler Overview
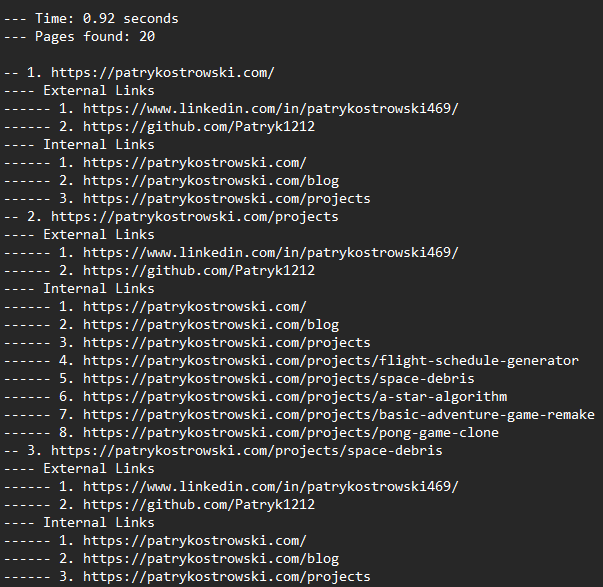
Given this was my simple side project in the area that I was interested in, this web crawler is limited to exploring a single domain that it is given. As it visits each page, it records the page URL along with the links discovered on that page, creating a structured map of the website. Links that belong to the same domain are followed and explored further, while external links pointing to other domains, such as GitHub profile links, for example, are identified, shown in the output, but not crawled. This approach allows the crawler to build a complete view of the website’s internal structure while keeping external references organised but excluded from exploration. It also:
- Avoids duplicate visits to same pages
- Normalises URLs
- Handles errors by saving information about pages that were unsuccessful and continues crawling
- Supports concurrent crawling (more on that on the next page)
- Filters unwanted URLs such media files
- Creates an output file with all details such as how much time it took, number of pages found or errors